Documentation Index
Fetch the complete documentation index at: https://docs.langbot.app/llms.txt
Use this file to discover all available pages before exploring further.
LangBot Models
LangBot Models 是 LangBot 官方提供的模型服务。当您使用 LangBot Space 账户初始化本地实例时,可用模型将被自动添加到您的实例中,无需进行任何配置。您将会获得一定的免费额度用于快速上手。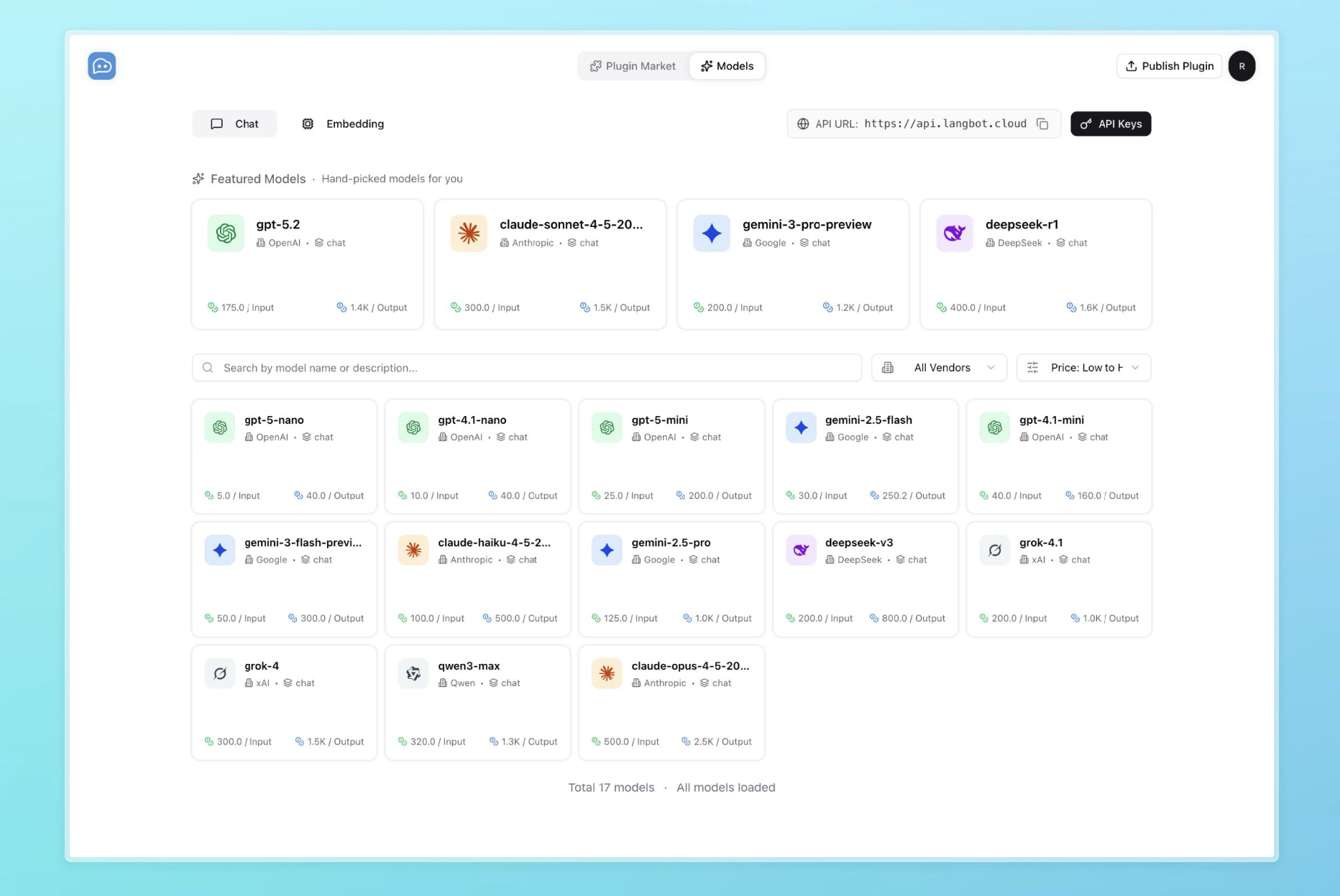
自定义模型
您也可以添加其他来源的模型。LangBot 采用 供应商(Provider)+ 模型(Model) 的两层架构:- 供应商:定义 API 地址(Base URL)和 API 密钥。同一供应商下的所有模型共享这些配置。
- 模型:关联到一个供应商,指定具体的模型名称和能力。
对话模型 (LLM Model)
对话模型将被流水线用于处理消息,您配置的第一个模型将被设置为默认流水线的模型。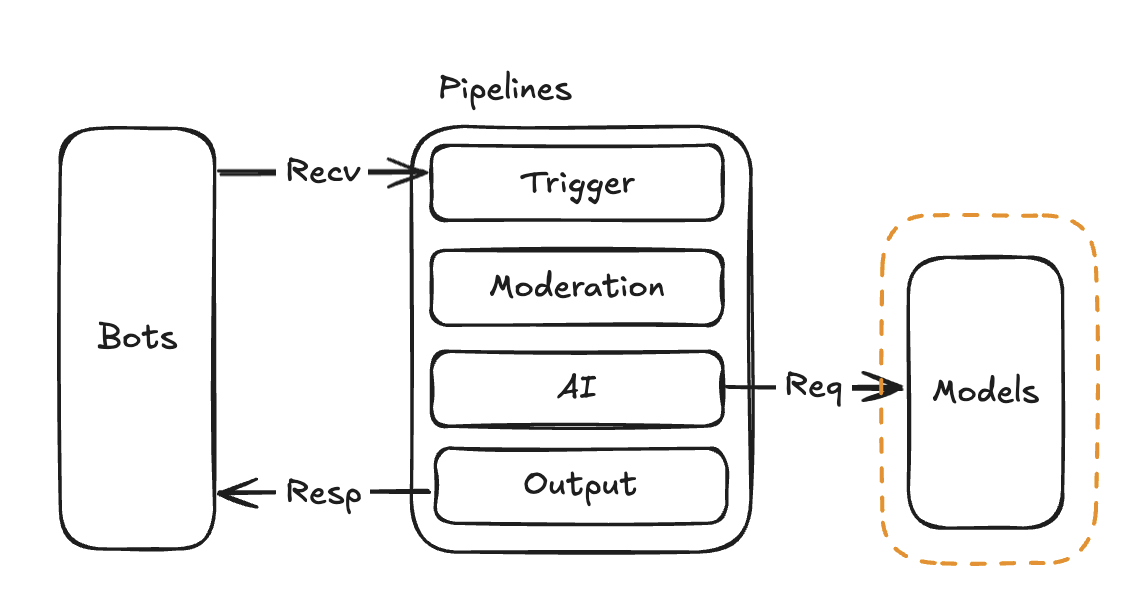
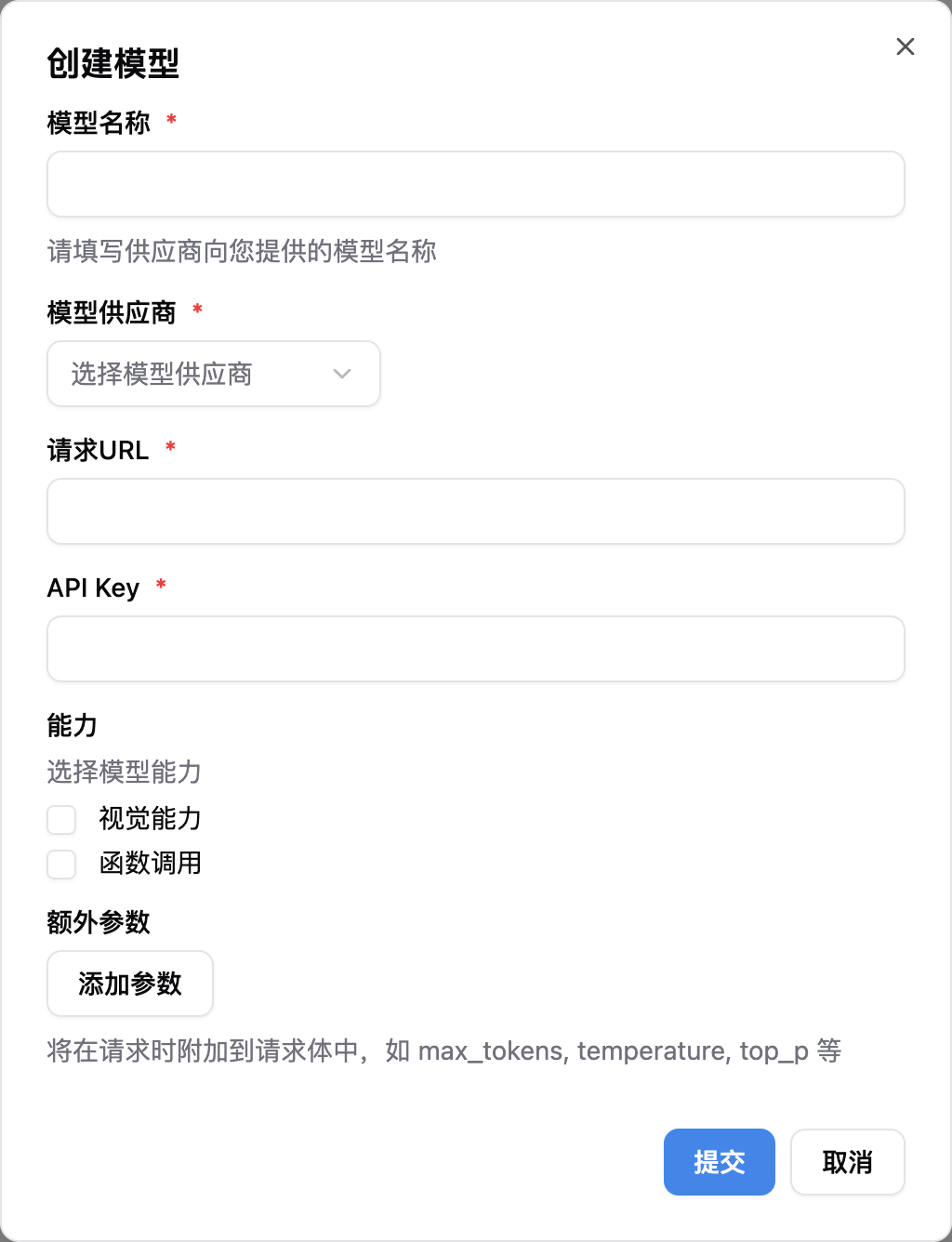
模型名称、选择 模型供应商(或新建供应商并填入 请求 URL 和 API Key),然后提交即可。
模型能力方面,请根据具体模型特性来选择:
- 视觉能力:需要启用才可以识图
- 函数调用:需要启用才可以在对话中使用 Agent 工具
嵌入模型 (Embedding Model)
嵌入模型将被用于计算消息的向量,若您需要使用知识库,请配置此模型。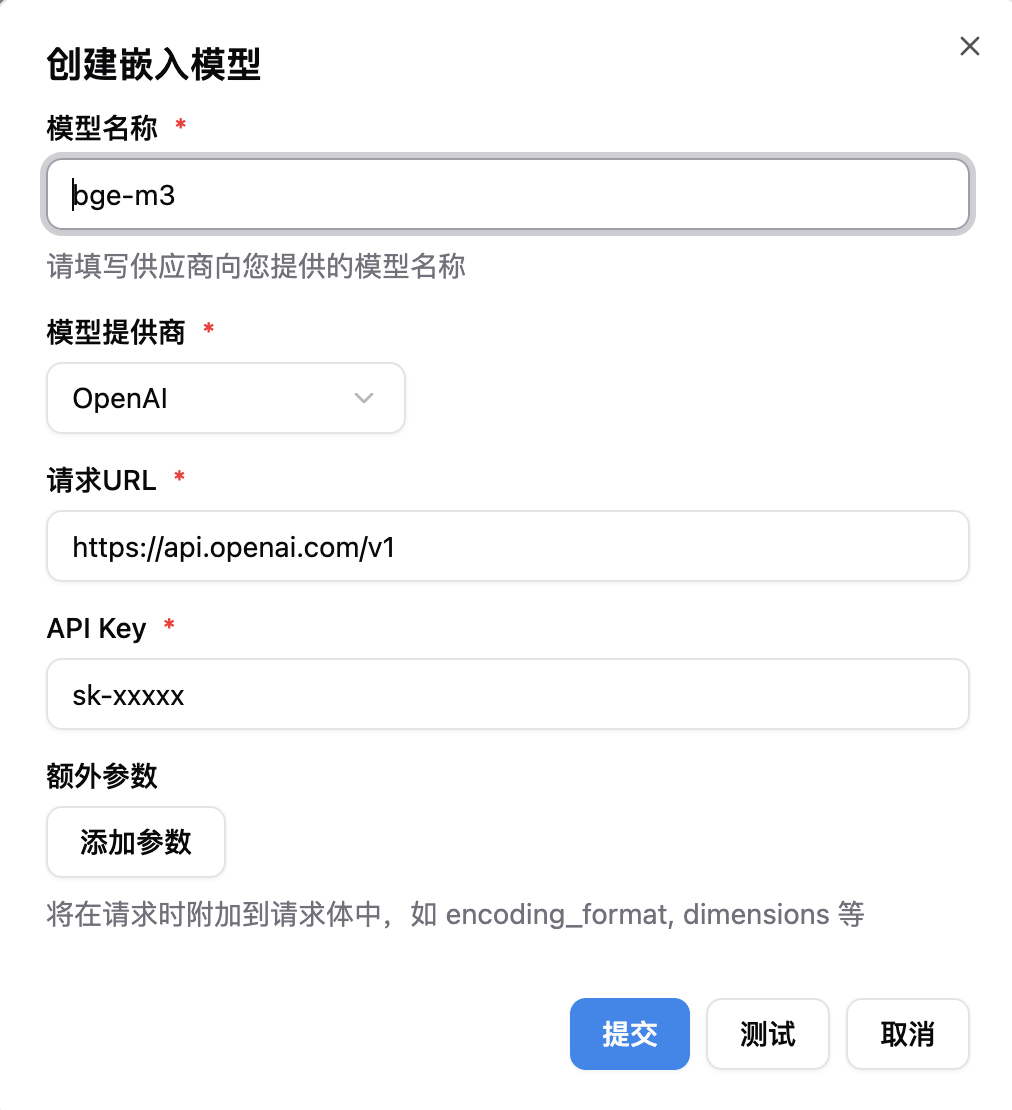
模型名称、选择 模型供应商,然后提交即可。之后请在知识库中配置使用此模型。
使用 seekdb 内置嵌入模型(零配置)
系统已集成 seekdb 提供的官方嵌入模型,无需填写任何参数。- 在”嵌入模型”页面选择「seekdb-内置」;
- 点击「保存」即可立即使用;
- 后续在知识库中选择该模型即可生效。
使用 Chroma 内置嵌入模型(零配置)
系统已集成 Chroma 提供的内置嵌入模型(all-MiniLM-L6-v2),无需填写任何参数。- 在”嵌入模型”页面选择「chroma-内置」;
- 点击「保存」即可立即使用;
- 后续在知识库中选择该模型即可生效。
重排序模型 (Rerank Model)
重排序模型用于对 RAG 检索结果进行重新评分排序,显著提升知识库回答的精准度。当知识库返回多个候选文档时,重排序模型会使用 cross-encoder 对每个文档与查询的相关性进行精确打分,筛选出最相关的内容。 填入模型名称、选择 模型供应商,然后提交即可。之后请在流水线的”AI 能力”配置中选择此模型。