ナレッジリトリーバーコンポーネントの追加
1つのプラグインには任意の数のナレッジリトリーバーを追加できます。プラグインディレクトリでコマンドlbp comp KnowledgeRetrieverを実行し、プロンプトに従ってナレッジリトリーバーの設定を入力します。
➜ FastGPTRetriever > lbp comp KnowledgeRetriever
Generating component KnowledgeRetriever...
KnowledgeRetriever name: fastgpt
KnowledgeRetriever description: Retrieve knowledge from FastGPT knowledge bases
Component KnowledgeRetriever generated successfully.
components/knowledge_retriever/ディレクトリにfastgpt.yamlとfastgpt.pyファイルが生成されます。.yamlファイルはナレッジリトリーバーの基本情報と設定パラメータを定義し、.pyファイルはこのリトリーバーのハンドラです:
➜ FastGPTRetriever > tree
...
├── components
│ ├── __init__.py
│ └── knowledge_retriever
│ ├── __init__.py
│ ├── fastgpt.py
│ └── fastgpt.yaml
...
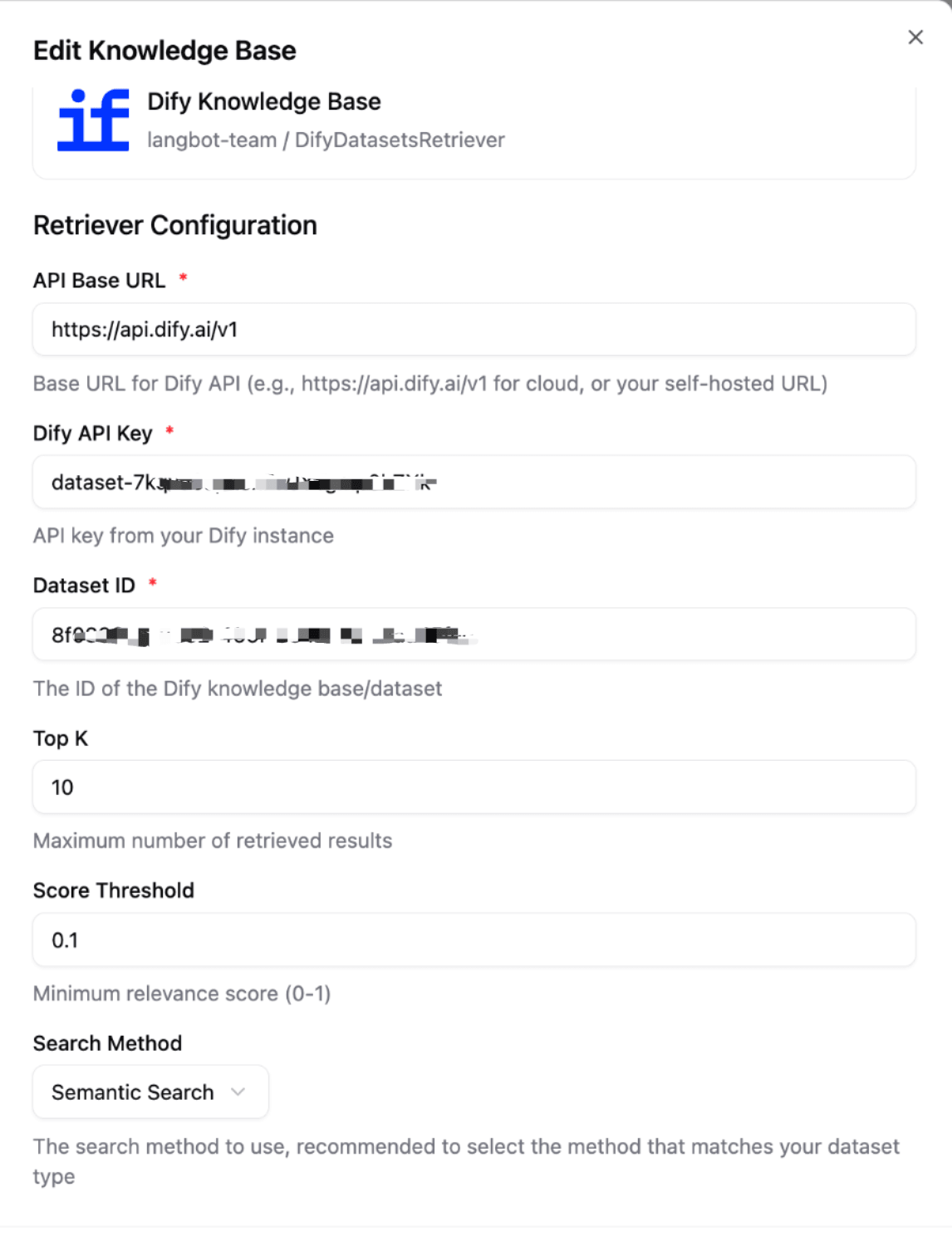
マニフェストファイル: ナレッジリトリーバー
apiVersion: v1 # 変更しないでください
kind: KnowledgeRetriever # 変更しないでください
metadata:
name: fastgpt # ナレッジリトリーバー名、このリトリーバーを識別するために使用
label:
en_US: FastGPT Knowledge Base # リトリーバー表示名、LangBotのUIに表示、多言語対応
zh_Hans: FastGPT 知識庫
ja_JP: FastGPT ナレッジベース
description:
en_US: 'Retrieve knowledge from FastGPT knowledge bases' # リトリーバー説明、LangBotのUIに表示、多言語対応。オプション
zh_Hans: '従 FastGPT 知識庫中検索知識'
ja_JP: 'FastGPT ナレッジベースから知識を取得'
icon: assets/icon.svg # リトリーバーアイコン、外部ナレッジベース設定ページに表示
spec:
config: # リトリーバー設定パラメータ、ユーザーは外部ナレッジベース作成時にこれらのパラメータを入力する必要があります
- name: api_base_url # パラメータ名
type: string # パラメータタイプ: string、number、boolean、select
label:
en_US: API Base URL
zh_Hans: API 基礎地址
ja_JP: API ベース URL
description:
en_US: 'Base URL for FastGPT API'
zh_Hans: 'FastGPT API 基礎地址'
ja_JP: 'FastGPT API ベース URL'
default: 'http://localhost:3000' # デフォルトパラメータ値
required: true # 必須かどうか
- name: api_key
type: string
label:
en_US: FastGPT API Key
zh_Hans: FastGPT API Key
ja_JP: FastGPT API キー
description:
en_US: 'API key from your FastGPT instance'
zh_Hans: '従您的 FastGPT 実例獲取的 API Key'
ja_JP: 'FastGPT インスタンスから取得した API Key'
default: ''
required: true
- name: search_mode # select型パラメータの例
type: select
label:
en_US: Search Mode
zh_Hans: 搜索模式
ja_JP: 検索モード
description:
en_US: 'The search method to use'
zh_Hans: '使用的搜索方法'
ja_JP: '使用する検索方法'
default: 'embedding'
options: # select型パラメータはオプションリストを定義する必要があります
- name: 'embedding'
label:
en_US: 'Embedding Search'
zh_Hans: '向量搜索'
ja_JP: '埋め込み検索'
- name: 'fullTextRecall'
label:
en_US: 'Full-Text Recall'
zh_Hans: '全文検索'
ja_JP: '全文検索'
- name: using_rerank # boolean型パラメータの例
type: boolean
label:
en_US: Use Re-ranking
zh_Hans: 使用重排序
ja_JP: リランキングを使用
description:
en_US: 'Whether to use re-ranking'
zh_Hans: '是否使用重排序'
ja_JP: 'リランキングを使用するかどうか'
default: false
required: false
execution:
python:
path: fastgpt.py # リトリーバーハンドラ、変更しないでください
attr: FastGPT # リトリーバーハンドラのクラス名、fastgpt.pyのクラス名と一致
プラグインハンドラ
以下のコードがデフォルトで生成されます(components/knowledge_retriever/<retriever_name>.py)。FastGPTクラスのretrieveメソッドでナレッジ検索ロジックを実装する必要があります。完全なコードはlangbot-plugin-demoで見つけることができます。
# Auto generated by LangBot Plugin SDK.
# Please refer to https://docs.langbot.app/en/plugin/dev/tutor.html for more details.
...
class FastGPT(KnowledgeRetriever):
async def retrieve(self, context: RetrievalContext) -> list[RetrievalResultEntry]:
"""FastGPTナレッジベースからナレッジを検索"""
# 1. 設定パラメータを取得
api_base_url = self.config.get('api_base_url', 'http://localhost:3000')
api_key = self.config.get('api_key')
dataset_id = self.config.get('dataset_id')
search_mode = self.config.get('search_mode', 'embedding')
using_rerank = self.config.get('using_rerank', False)
# 2. パラメータ検証
if not api_key or not dataset_id:
logger.error("Missing required configuration: api_key or dataset_id")
return []
# 3. APIリクエストを構築
url = f"{api_base_url.rstrip('/')}/api/core/dataset/searchTest"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"datasetId": dataset_id,
"text": context.query, # RetrievalContextからクエリテキストを取得
"searchMode": search_mode,
"usingReRank": using_rerank,
}
try:
# 4. 外部APIを呼び出す
async with httpx.AsyncClient() as client:
response = await client.post(url, json=payload, headers=headers, timeout=30.0)
response.raise_for_status()
result = response.json()
# 5. レスポンスを解析してRetrievalResultEntryに変換
results = []
for record in result.get('data', []):
# メインデータと補助データをコンテンツとして結合
content_text = '\n'.join([
record.get('q', ''),
record.get('a', '')
]).strip()
# 検索結果エントリを作成
entry = RetrievalResultEntry(
id=record.get('id', ''),
content=[ContentElement.from_text(content_text)],
metadata={
'dataset_id': record.get('datasetId', ''),
'source_name': record.get('sourceName', ''),
'score': record.get('score', 0.0),
},
# 類似度スコアを距離に変換(スコアが高いほど距離が小さい)
distance=1.0 - float(record.get('score', 0.0)),
)
results.append(entry)
logger.info(f"Retrieved {len(results)} chunks from FastGPT dataset {dataset_id}")
return results
except httpx.HTTPStatusError as e:
logger.error(f"HTTP error from FastGPT API: {e.response.status_code} - {e.response.text}")
return []
except httpx.RequestError as e:
logger.error(f"Request error when calling FastGPT API: {str(e)}")
return []
except Exception as e:
traceback.print_exc()
logger.error(f"Unexpected error during retrieval: {str(e)}")
return []
検索コンテキスト
RetrievalContextにはこの検索のコンテキスト情報が含まれます:
class RetrievalContext(pydantic.BaseModel):
"""ナレッジ検索コンテキスト"""
query: str
"""クエリテキスト、ユーザーの検索質問"""
検索結果
検索結果はRetrievalResultEntryオブジェクトのリストに変換する必要があり、各オブジェクトは検索されたナレッジチャンクを表します:
class RetrievalResultEntry(pydantic.BaseModel):
"""単一検索結果エントリ"""
id: str
"""結果ID、このエントリを一意に識別"""
content: list[ContentElement]
"""結果コンテンツ、ContentElement.from_text()を使用してテキストコンテンツを作成"""
metadata: dict[str, Any]
"""結果メタデータ、ソース、スコアなど、任意のキーと値のペアを含めることができます"""
distance: float
"""距離スコア、クエリとの関連性を示します(小さいほど関連性が高い)
通常は1.0 - similarity_scoreとして計算されます"""
設定パラメータの取得
self.config.get(パラメータ名, デフォルト値)を使用して、ユーザーが設定したパラメータ値を取得します:
# 文字列パラメータを取得
api_base_url = self.config.get('api_base_url', 'http://localhost:3000')
# 数値パラメータを取得
limit = self.config.get('limit', 5000)
similarity = self.config.get('similarity', 0.0)
# ブールパラメータを取得
using_rerank = self.config.get('using_rerank', False)
# selectパラメータを取得
search_mode = self.config.get('search_mode', 'embedding')
リトリーバーのテスト
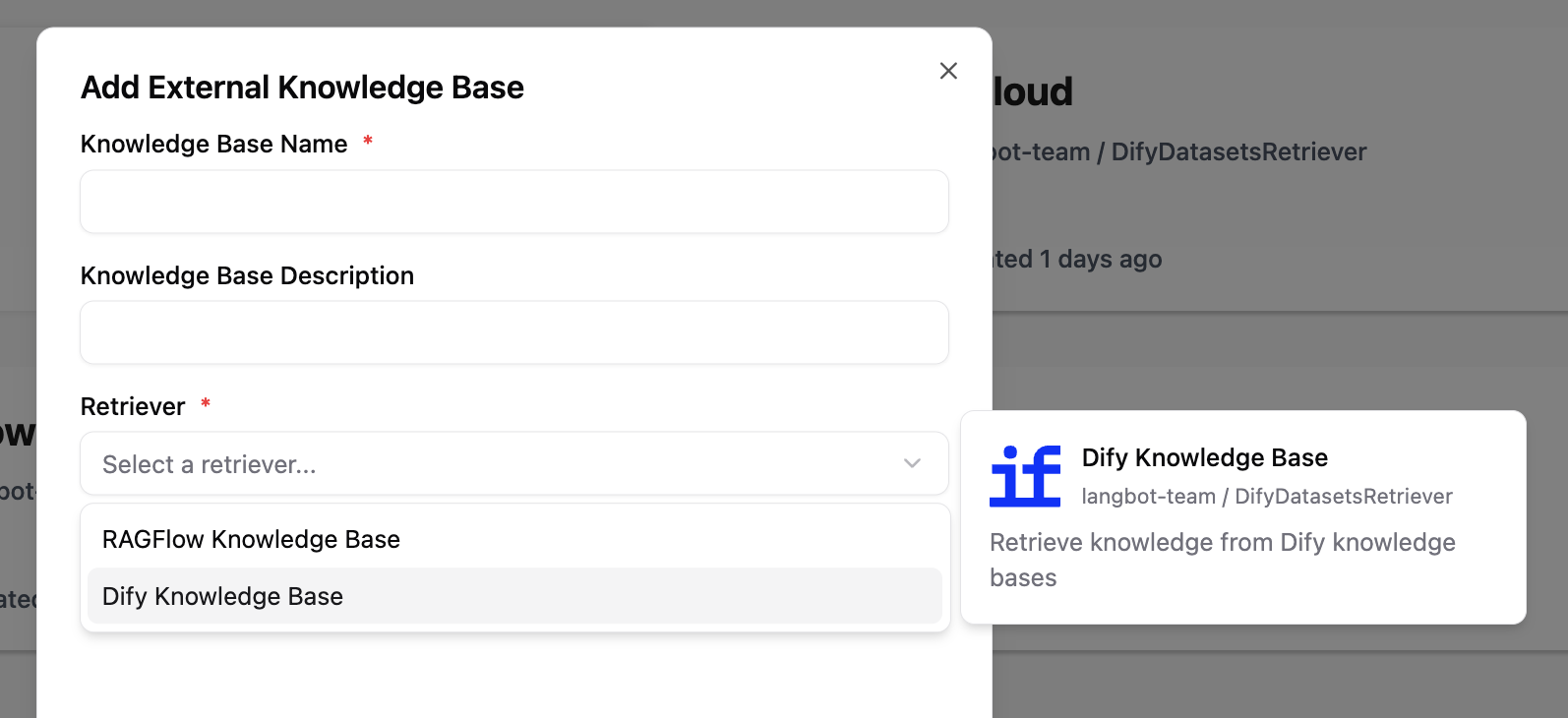
作成後、プラグインディレクトリでコマンドlbp runを実行してデバッグを開始します。その後、LangBotで:
- 「ナレッジベース」ページに移動
- 外部ナレッジベースを追加
- プラグインが提供するナレッジリトリーバーを選択し、設定を入力